Best Practices: Training a Deep Learning Neural Network
Introduction
The most important determinant of deep learning system efficacy is the dataset developers use to train it. A high-quality training dataset improves inference accuracy and speed while reducing system resources and accelerating the learning process.
If developers need to run deep learning inference on a system with highly limited resources, they can optimize the trained neural network accordingly and eliminate the need for a host system. Much smaller devices like FLIR Firefly DL camera can run inference based on your deployed neural network on its integrated Movidius™ Myriad™ 2 processing unit.
This article describes how to develop a dataset for classifying and sorting images into categories, which is the best starting point for users new to deep learning.
How much training data do I need?
The amount of training data required depends on the following factors:
- Number of data classes to be distinguished, e.g. “Apple”, “Leaf”, “Branch”.
- Similarity of classes to be distinguished, e.g. “Apple” vs. “Pear” is more complex than “Apple” vs. “Leaf”.
- Intended variance within each class, e.g. apples of different colors and shapes, for more robustness against variations in the real-life application scenario.
- Unwanted variance in the image data, e.g. noise, differences in white balance, brightness, contrast, object size, viewing angle, etc.
A few hundred images may be enough to deliver acceptable results, while more complex applications could require over a million images. The best way to determine your training data requirements is to gather data and test your model with it. Finding problems like the one you are solving can also provide a good starting point for estimating dataset size.
Your network will eventually reach a point where additional data does not improve model accuracy. It is unlikely your model will achieve 100% accuracy no matter how big your training dataset is. Understanding the balance of speed and accuracy required by your specific application will help you determine whether additional training data is required.
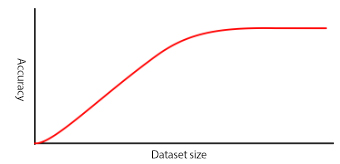
Test with validation data
Your image dataset must be large enough to provide validation data, which will be used to assess the accuracy and speed of the network as it is trained. These images should be randomly selected from the dataset to ensure they are representative as far as possible.
In case of small datasets or if enough time and computational power is available, the recognition performance can also be determined by multi-fold validation. Here, a dataset is split into e.g. five random segments. Hence, a neural net is trained with four segments and validated with the remaining segment. This training and validation are repeated for all five combinations of training and validation segments. The mean value of the recognition rates indicates the performance to be expected. The standard deviation tells how representative the dataset is.
Improving your dataset
Deep learning is an iterative process. Networks make predictions about training data, which are used to improve the network. This process is repeated until the network achieves the desired level of accuracy. The larger the dataset, the more variance which may occur in the target application is presented to the Deep Learning algorithm. Very small datasets do not provide enough information for the algorithm to work properly. As a result, you may see good recognition performance on the training data but a recognition rate around the guess probability on validation data. A well-planned training data acquisition phase that yields accurately labeled images with a minimum of unnecessary variation reduces the amount of training data required, speeds training, and improves inference accuracy and speed.
Minimize differences between training images and production images
Capturing images with the same cameras, optics, and lighting as the future production system eliminates the need to compensate for differences in geometry, illumination, and spectral response between training and live image data. High-quality cameras with Pregius® sensors, GenICam® interfaces, and rich GPIO functionality make it easier to automate acquisition of good training datasets.
Using controlled environments to reduce dataset
A good training dataset includes examples of variation where expected and minimizes variance where it can be eliminated by system design. For example, inspecting apples while they are still on the tree is much more complex than inspecting the same apples on a conveyor belt. The outdoor system needs training to recognize apples at different distances, orientations, and angles, and must account for changing lighting and weather conditions. A model that performs consistently requires a very large dataset.
Taking images of apples in a controlled environment allows system designers to eliminate many sources of variance and achieve high-accuracy inference using a much smaller dataset. This, in turn, reduces the size of the network and enables it to run on compact, stand-alone hardware like the FLIR Firefly DL camera, powered by Intel Movidius Myriad 2.


Fig. 1. Images captured under controlled conditions (A) have less variance than images captured under uncontrolled conditions (B).
Improve results with accurately labeled data
Labels are used to test predictions made during training. Labels must represent the images they belong to; inaccurate or “noisy” labels are a common problem with datasets assembled using internet image searches. Appending labels to image file names is a good idea as it reduces potential confusion while managing and using training data.


Fig. 2. Examples of well selected (A) and poorly selected images (B) for the category “apple”.
Labeling data for segmentation is much more complex and time consuming than classification.

Fig. 3. Labeling images for segmentation is much more complex than for classification.
Improving the quality & quantity of an existing dataset
Augmentation to expand data set
Some systems, such as those for fruit inspection, examine objects whose orientation is not controlled. For these systems, data augmentation is a useful way to quickly expand the dataset using affine and projective transformations. Color transformation can also expose the network to a greater variety of images. Developers must crop transformed images to maintain the input dimensions the neural network needs.

Fig. 5. Examples of transformations including rotation, scaling and shearing.
Normalisation for improved accuracy
Normalising data makes neural network training more efficient. Normalized images look unnatural to humans, but they are more effective for training accurate neural networks. Developers can normalise pixel and numerical values the same way.


Fig. 6. Original image (A) vs. image using the common Y = (x - x.mean()) / x.std() normalisation method
Synthetic data
In situations requiring large amounts of training data that cannot be created using dataset augmentation, synthetic data is a powerful tool. Synthetic data is artificially generated imagery which can be used to quickly generate large amounts of pre-labelled, perfectly segmented data. However, synthetic data alone is not enough to train a network that delivers accurate, real-world results. Enhancing the realism of synthetic data requires post-processing.
Conclusion
A high-quality training dataset improves inference accuracy and speed while reducing system resources and accelerating the training process. There are methods for increasing both the quantity and quality of the dataset. The FLIR Firefly camera is a great option for designers who want to minimize system size, achieve high-accuracy inference, acquire training datasets, and deploy their neural network.
Learn more at www.flir.com/firefly-dl.
Related Articles
-
 Embedded Vision
Embedded Vision
Streaming 4x Cameras with Small Carrier Board: Fast Prototype
Read the Story -
 Embedded Vision
Embedded Vision
How to Build a Custom Embedded Stereo System for Depth Perception
Learn more -
 Embedded Vision
Embedded Vision
Guide for Integrating Board Level Cameras
Read the Story